
These activities are an investment that yields business value… streamlining work and rapidly delivering value to customers...
Machine Learning Operations (MLOps)
Machine learning operations (MLOps) are the formal processes and requirements that govern activities within a data science project and facilitate its success. MLOps project management enables a team to motivate the project, define the problem, scope the work, and formalize communication. Efficient project execution, the focus of this article, reduces or eliminates common project failure modes by leveraging workflow, development, testing, and experimentation activities.
- Project workflows act as guardrails to help plan, organize, and implement data science projects.
- Project development structures the sequence of steps to generate software components.
- Project testing ensures code, data, and models perform as expected.
- Project experimentation verifies expected outcomes and discovers areas for improvement.
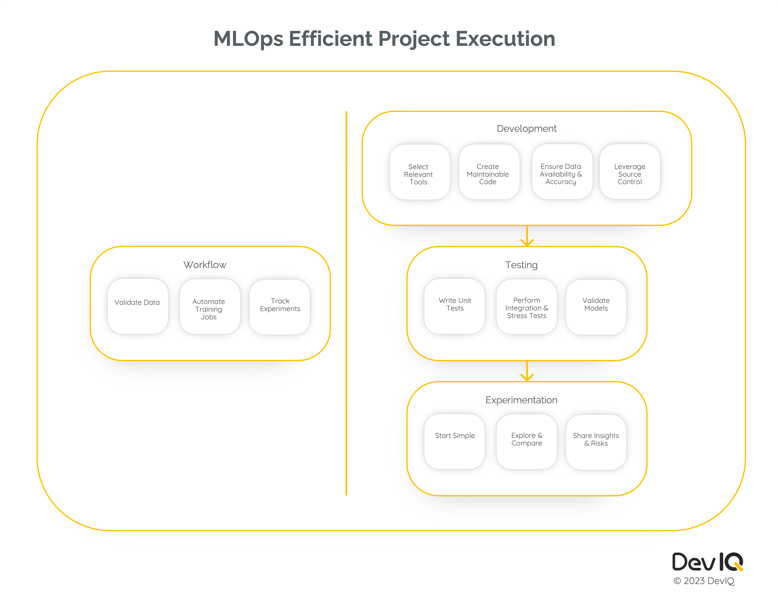
Project Workflow for MLOps
Implementing an MLOps workflow produces the framework to rapidly improve team and code efficiency, which benefits both team members and stakeholders. Team members are aided by the workflow because it forces code to be modularized and replicable to support changes in project requirements. The workflow benefits stakeholders by allowing them to provide continual project evaluation and team collaboration.
Validate data
Workflows validate data before subsequent training and prediction tasks. This requires careful coordination with procurement, legal, and IT for data vendor selection. External data sources must be thoroughly vetted for accuracy, cost, and security. Streamlining data evaluation and ingestion improves validation and expedites subsequent workflow steps.
Automate training jobs
A robust data engineering pipeline is essential to ensure that feature creation, transformation, and manipulation are consistent and concise. A model training pipeline should assess different algorithms and parameters to determine the best-performing model.
Track experiments
Tracking experiments requires recording all software and hardware dependencies. A feature store and model registry can manage data and models to ensure replicability and transition to production environments. Measuring the downstream consumption of results provides insight into their impact on key performance indicators (KPIs).
Project Development for MLOps
Development creates and assembles all software components while enforcing proper guidelines for code style and best practices. It is critical to integrate security assessments into the process to reduce risks and ensure long-term success.
Select relevant tools
Tools should align with project requirements and production environments. Establishing criteria for tool selection reduces planning time and simplifies transitions between projects.
Create maintainable code
Maintainable code enables rapid responses to changes in project requirements. Containers or virtual machines ensure identical environments for development and production, reducing bugs and improving reliability.
Ensure data availability and accuracy
Metadata visibility and artifact versioning in a feature store allow developers to test with validated inputs. Proper access controls ensure secure and reusable datasets.
Leverage source control
Source control versions code, data, and models to maintain consistency between development and production environments. Proper artifact management ensures smooth deployments and reliable backups.
Project Testing for MLOps
Testing ensures the project can meet business objectives, improves code quality, and resolves errors before production deployment.
Write unit tests
Unit tests establish high data quality benchmarks and ensure reliability in feature creation, model training, and inference methods.
Perform integration and stress tests
Integration and stress tests validate the pipeline's scalability. Testing each stage individually and collectively ensures robust performance.
Validate models
Models must be tested for relevance and correctness with sample input data. Monitoring bias, variance, and drift ensures reliability in production.
Project Experimentation for MLOps
Experimentation tests hypotheses, compiles performance metrics, and identifies model infrastructure requirements.
Start simple
Begin with simple models to avoid overcomplexity. Tune hyperparameters to achieve optimal configurations and focus on business objectives.
Explore and compare
Evaluate new data sources and algorithms while investigating ensemble learning to enhance performance metrics.
Share insights and risks
Regularly deliver insights, share feedback, and evaluate operational risks before transitioning workflows to production.
Investing in Efficiency
Efficient execution of data science projects relies on workflows, development, testing, and experimentation. Together, these activities streamline processes and rapidly deliver value to customers.
This article is part of DevIQ's series on MLOps. Continue exploring this topic:
